
多言語対応への布石 (1)チベット語辞書の検索
今回は、テスト実装のターゲットとして、Unicode規格でも定義されているチベット語を選んでみました。
※チベット語、あるいはチベットに関する質問にはお答えしかねますのでご了承ください。
使用する辞書データは、Rangjung Yeshe という市販($40)の蔵英(Tibetan-English)辞書(用の検索ソフトに付属していたサンプルデータを変換したもの)です。
元データはこんな感じです:
ka kha - 1) the alphabet [Tibetan]. 2) alphabetical register. 3) feather.
ka kha pa - a person beginning to study the alphabet, schoolboy, abecedarian.
ka kha'i dpe - alphabetic index, alphabet, primer. syn {ka kha'i tho}
ka kha'i klog thabs - Tibetan primer
ka kha'i rim pa - alphabetic order. syn {ka kha'i tho} alphabetic index.
ka kha'i tho - 1) alphabetic index. 2) primer. 3) alphabetic order.
" - " の左側にあるのが、チベット語の単語をローマ字に転写したものです。転写方式もいくつかあって、これはWylieという方式です。
行の最初にある " - " を " /// " に置換すればそのまま PDIC1行テキスト形式になるので、ユーティリティでPDICに変換して検索できます。これなら、単語欄にも訳語欄にも7bit ASCIIの範囲内の文字しか使っていないので、フォントもコード変換も不要、従って現行のバージョンで対応可能です。
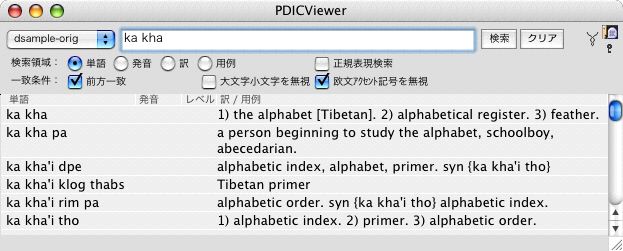
これで十分、というのでしたら、とりあえずこの先は読み飛ばし
![]() て頂いて結構です。
て頂いて結構です。
チベット文字での表示
さて、今度はこれをチベット文字で表示させてみたいと思います。
チベット語は Unicode 規格に含まれていて、コード領域も割り当てられている(0F00-0FFF)ので、
Wylie転写されたローマ字をチベット文字に変換し、PDIC Unicode (BOCU) 辞書に変換したものでトライしてみます。
PDIC Viewer 1.0.2から、テキスト形式からの辞書変換が UTF-8 テキストに対応した※ので、元データをちょっとした自作スクリプトに通して、PDIC1行テキスト形式(UTF-8版)ファイルを生成し、BOCU辞書を作ってみました。早速これで検索してみます。
UTF-8テキストに対応させたのは、この実験のためでもあります。
UTF-8ファイルかどうかを判定するルーチンを自作しました。 8ビットコードが含まれ、UTF-8エンコーディングとして辻褄が合っていればUTF-8、さもなければShiftJIS(というか無変換)ということにしています。例外がある可能性もありますが未検証です。
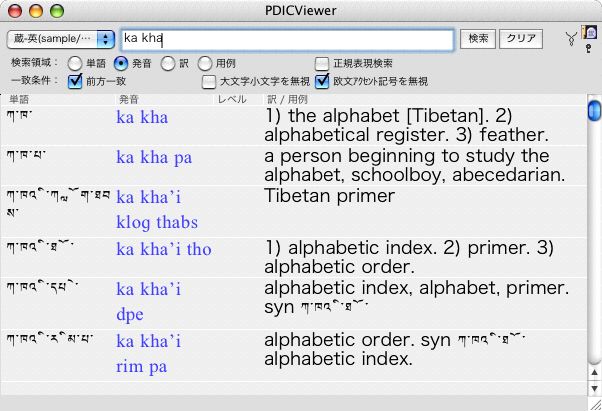
単語欄をUnicodeのチベット文字にしてしまうと、(チベット語のインプットメソッドが無い現状では)検索語の入力に困るので、便宜的に発音欄に元データのローマ字をコピーして入れてあります。
この便宜をはかる為に、PDIC1行テキストのUTF-8対応に加え、タブ区切りテキスト(こちらもUTF-8可)からの変換にも対応させてしまいました。
結果は(上図をご覧の通り)ダメダメです。
チベットの表記をご存知でない方は、この下の方のスナップショット(成功例!)が目標としている表記なのでご参照頂くとして、結論は、Mac OS X(※10.3.7)では Unicode のチベット語はうまく描画できないようだ、という事です。
Carbonアプリではテキスト描画に CFString 構造体を使っています。内部的にはこれはどうやら Unicode らしいのですが、Unicode で定義されている全ての言語で満足に描画可能なわけではないようです。
ちなみに、BOCU辞書に変換する前のUTF-8ファイルをWebブラウザで見てみると、Firefoxでは上のスナップショット同様ですが、Safari ではかなりまともに表示されました。Firefox が(PDIC Viewerと同じ Carbon で、Safari が Cocoa なせいでしょうか。
Unicodeが駄目なら、旧来の方法(即ち指定フォントの使用、そして必要ならば内部でのコード変換)で実現するまでの事です。
ここでは、見栄え的に気に入った「TCRC Youtsoweb」フォント(チベット亡命政府のHPで使われていたもの)をMac用にコンバートしたものを使っています。
OS XではWindowsのTrueTypeフォントもそのままインストールして使えるのですが、8ビット領域でOSが勝手にコード変換してしまうので、思ったような結果になりません。(Win←→Macのコード変換テーブルが1対1の写像になっていないので対処のしようもない)
辞書データは(検索の便宜のため、BOCU辞書ではなく)Wylie方式で転写したローマ字辞書を用いることにして、指定の辞書ファイルを開いた場合、内部でTCRC Youtsowebフォントの文字テーブルに変換して表示させるようにしてみました。
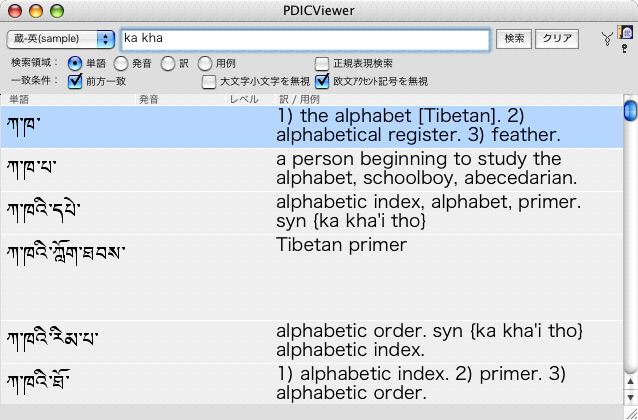
一応、目標としていた表示は可能になりました。 文字コードの内部コンバートによる表示の遅延は(体感的には全く)ありません。 しかも検索はWylieでそのままできるので、普通の英語辞書と変わらない検索ができます。
問題点は、検索結果の並び順が(英語の、あるいはASCIIコード的な)アルファベット順であることです。
PDIC辞書は、その仕様上、現状ではアルファベット順(=ASCIIコード順)の並びの辞書しか作ることができません。(そうでないものがあったとしても、使うことができません)
辞書の並び順を決めるファクターを文字列から計算し、それを元にソートをかける、ということは可能なので、そういう方向で落ち着くと思います。(チベット語の辞書順はちょっと複雑ですが・・・)
でも、とりあえず検索できて、さらにチベット文字で表示できる、というのは1つのテストケースとして評価できるかと思います。(Unicodeに入っていない言語にでも、フォントと適切なローマ字転写方式さえあれば対応できる可能性がある、という意味でも)
TLKフォントへの対応
TCRC Youtsowebフォントは、Windows形式からの変換が必要なため、利用には敷居が高いのが現状です。
そこで、Macintosh用に開発されたチベット語フォントの利用について検討します。
大谷大学真宗総合研究所(京都)で配布しているTibetan Language Kit (以下TLK) のフォントを使えるようにするのが目標です。
現在のところ、こんな感じです:
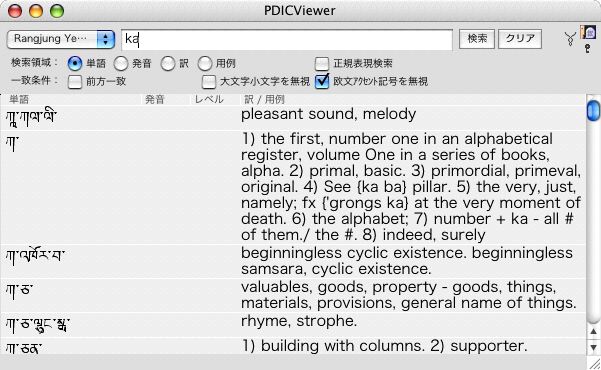
有足字 (-y -l -r -w) 用のフォントが何種類もあることから、適切な組み合わせを(TLKをハックして)探す必要がありそうです。
(でも何とかなりそうです)
![]()
copyright ©2003-2005 NAOCHAN.COM. All Rights Reserved.